A Ciência de Dados tem sido considerada a profissão mais sexy do século 21. Sendo um campo interdisciplinar, ela incorpora métodos científicos, algoritmos, sistemas e processos no estudo e gerenciamento de dados. Trabalhar nessa área envolve lidar com processos como engenharia de dados, visualização de dados, computação avançada e aprendizado de máquina (machine learning).
Felizmente, há uma variedade de ferramentas poderosas que tornam todos os itens acima alcançáveis para os cientistas de dados. Uma grande parte de se tornar um cientista de dados é entender como utilizar essas ferramentas de forma significativa em sua função. E um dos conjuntos de ferramentas envolve as linguagens de programação.
Provavelmente você já saiba que Python é a linguagem mais popular nessa área, mas ela não é a única. Neste artigo, vamos trazer as principais linguagens de programação usadas em Ciência de Dados. Surpreenda-se!
SQL
Vamos começar com a mais óbvia. Desde que surgiu, em 1974, o SQL (Structured Query Language) tem ganhado consistência e ao longo dos anos tornou-se uma linguagem de programação popular para gerenciar dados.
Embora não seja usado exclusivamente para operações de Ciência de Dados, o conhecimento de tabelas e consultas SQL pode ajudar os cientistas de dados a lidar com sistemas de gerenciamento de banco de dados. Essa linguagem específica de domínio é extremamente conveniente para armazenar, manipular e recuperar dados em bancos de dados relacionais.
Existem vários tipos de bancos de dados, como MySQL, PostgreSQL e Microsoft SQL Server. Como a maioria deles reconhece SQL, é fácil trabalhar em qualquer um deles se você tiver um conhecimento profundo de SQL.
Mesmo se você estiver trabalhando com outra linguagem, como Python ou R, ainda precisará conhecer SQL para acessar e gerenciar o banco de dados para trabalhar com as informações. O melhor sobre o SQL é que, devido à sua sintaxe declarativa e simples, ele é muito fácil e rápido de aprender, além de ser bastante útil nas diversas funções envolvendo a Ciência de Dados.
Python
Python é a linguagem de programação mais usada no mundo atualmente na área de Ciência de Dados. É uma linguagem de código aberto e fácil de usar que existe desde o ano de 1991. Essa linguagem dinâmica e de propósito geral é inerentemente orientada a objetos. Ela também suporta vários paradigmas, desde programação funcional até programação estruturada e procedimental.
Por ter uma sintaxe bem mais simples e ser tão ampla, acabou sendo adotada como a linguagem preferida para uso em Ciência de Dados. Com menos de 1000 iterações, é mais rápida e melhor opção para manipulação de dados.
O processamento natural de dados e o aprendizado de dados tornam-se uma facilidade enorme devido aos inúmeros pacotes e bibliotecas contidos no Python. Além disso, o Python torna mais fácil para os programadores lerem os dados em uma planilha criando uma simples saída CSV.
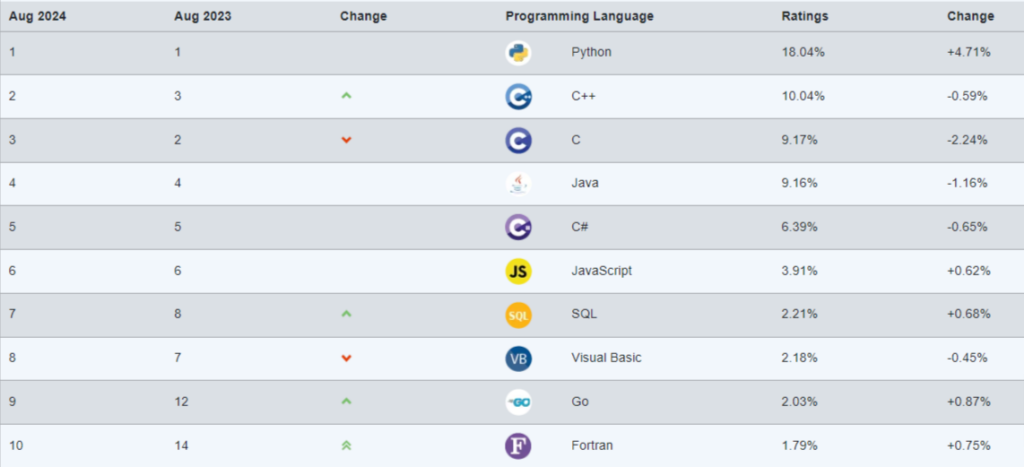
Python tem ranqueado em primeiro lugar nos principais índices de popularidade de linguagens de programação já há algum tempo, em grande parte devido ao crescimento da Ciência de Dados:
Índice TIOBE (atualizado em agosto de 2024):
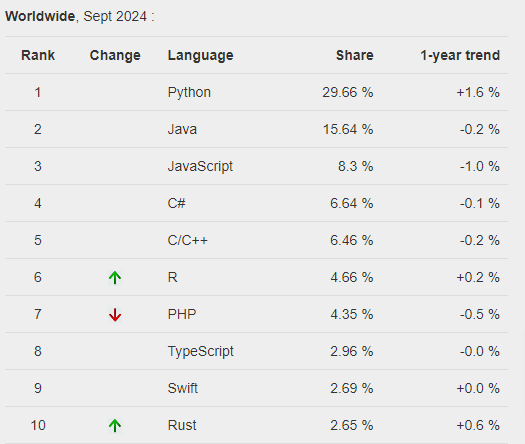
Índice PYPL (atualizado em setembro de 2024):
Não é à toa que Python se tornou a linguagem mais popular em Ciência de Dados, pois qualquer tarefa nesta área que você possa imaginar pode ser feita com Python. Isso se deve principalmente ao seu rico ecossistema de bibliotecas.
Com milhares de pacotes poderosos apoiados por sua enorme comunidade de usuários, o Python pode realizar todos os tipos de operações, desde pré-processamento de dados, visualização e análise estatística até a implantação de modelos de aprendizado de máquina (machine learning) e aprendizado profundo (deep learning).
Aqui estão algumas das bibliotecas mais usadas para fins de ciência de dados e aprendizado de máquina:
- NumPy: é um pacote popular que oferece uma extensa coleção de funções matemáticas avançadas. Muitos pacotes são baseados em objetos Numpy, como os famosos arrays NumPy.
- pandas: é uma biblioteca chave em Ciência de Dados, usada para realizar todo tipo de manipulação de banco de dados, também chamada de DataFrames.
- Matplotlib: a biblioteca padrão do Python para visualização de dados.
- scikit-learn: construído sobre NumPy e SciPy, tornou-se a biblioteca Python mais popular para o desenvolvimento de algoritmos de aprendizado de máquina (machine learning).
- TensorFlow: desenvolvido pelo Google, é um poderoso framework computacional para desenvolvimento de algoritmos de aprendizado de máquina e aprendizado profundo.
- Keras: uma biblioteca de código aberto projetada para treinar redes neurais com alto desempenho.
Devido à sua sintaxe simples e legível, o Python é frequentemente referido como uma das linguagens de programação mais fáceis de aprender e usar para iniciantes. Se você é novo em Ciência de Dados e não sabe qual linguagem aprender primeiro, o Python é uma das melhores opções.
R
R é uma linguagem de programação de alto nível construída por e para estatísticos. Antes restrita ao mundo acadêmico, com a popularização da Ciência de Dados, a linguagem R teve um crescimento exponencial nos últimos anos, sendo hoje uma das mais utilizadas e conhecidas no mundo.
A linguagem e o software de código aberto são normalmente usados para computação estatística e gráficos. Mas também tem várias aplicações em Ciência de Dados, já que esta área caminha ao lado da Estatística.
O R possui várias bibliotecas úteis para Ciência de Dados. Ele pode ser útil para explorar conjuntos de dados e realizar análises ad hoc. No entanto, os loops têm mais de 1.000 iterações e são mais complexos de aprender do que o Python.
É comum que cientistas de dados dominem R ao lado de Python, utilizando cada uma para propósitos distintos: enquanto Python tem pacotes poderosos para machine learning, por exemplo, o R se torna mais útil para análises estatísticas.
Java
Atualmente ranqueado em 2º lugar no índice PYPL e em 3º no índice TIOBE, o Java tem sido uma das linguagens de programação mais usadas e amadas por décadas. É uma linguagem orientada a objetos de código aberto, conhecida por seu desempenho e eficiência de primeira classe. Tecnologias infinitas, aplicativos de software e sites contam com o versátil ecossistema Java.
Embora o Java seja a escolha preferida no desenvolvimento de sites ou na criação de aplicativos do zero, nos últimos anos, ganhou um papel de destaque no setor de Ciência de Dados. Isso se deve principalmente às Java Virtual Machines (JVM), que fornecem uma estrutura sólida e eficiente para ferramentas populares de Big Data, como Hadoop, Spark e Scala.
Devido ao seu alto desempenho, Java é uma linguagem adequada para desenvolver trabalhos de ETL e executar tarefas de dados que exigem grande armazenamento e requisitos de processamento complexos, como algoritmos de aprendizado de máquina.
Se comparado ao Python, o Java é muito mais complexo e demorado para aprender. A sua popularidade na área de Ciência de Dados se deve em grande parte pela quantidade de desenvolvedores que resolveram migrar para essa área de dados. Ou seja, se você já conhece Java, é muito mais fácil aprender algumas bibliotecas direcionadas à Ciência de Dados do que aprender uma linguagem completamente diferente, como R ou Julia.
Julia
Julia pode ser considerada uma estrela em ascensão na área de Ciência de Dados. Apesar de ser uma das linguagens mais novas dessa lista (foi lançada em 2011), Julia é uma linguagem de programação de Ciência de Dados que foi desenvolvida especificamente para análise numérica rápida e ciência computacional de alto desempenho. Ela pode implementar rapidamente conceitos matemáticos como álgebra linear e é uma excelente linguagem para lidar com matrizes.
Às vezes referida como a herdeira do Python, Julia é uma ferramenta altamente eficaz em comparação com outras linguagens usadas para análise de dados. Julia também pode ser usada para programação de back-end e front-end, e sua API pode ser incorporada em programas.
Embora tenha ganhado notoriedade graças à sua adoção antecipada por várias organizações importantes, incluindo muitas do setor financeiro, Julia ainda não tem maturidade para competir com as principais linguagens de Ciência de Dados. Sua comunidade ainda é pequena e não possui tantas bibliotecas quanto seus principais concorrentes, Python ou R.
Apesar disso, há inúmeras razões para ficar de olho nela. Afinal, toda linguagem passou por seus períodos de amadurecimento. Vamos ver como evolui nos próximos anos.
Scala
Essa linguagem de programação moderna e elegante foi criada mais recentemente, em 2003. É uma linguagem multiparadigmática explicitamente projetada para ser uma alternativa mais clara e menos prolixa ao Java.
Suas aplicações vão desde programação web até aprendizado de máquina. É também uma linguagem escalável e eficaz para lidar com Big Data. Nas organizações modernas, o Scala oferece suporte à programação funcional e orientada a objetos, bem como ao processamento simultâneo e sincronizado.
Scala também roda na Java Virtual Machine (JVM), permitindo interoperabilidade com Java e tornando-a uma linguagem perfeita para projetos de Big Data distribuídos. Por exemplo, a estrutura de computação de cluster Apache Spark é escrita em Scala.
JavaScript
JavaScript é outra linguagem multiparadigma e versátil, amplamente conhecida por sua capacidade de construir páginas web ricas e interativas, e por isso também está entre as mais populares do mundo.
Embora a maioria dos usuários de JavaScript trabalhe com desenvolvimento web, nos últimos anos a linguagem ganhou notoriedade no setor de Data Science. Hoje, o JavaScript oferece suporte a bibliotecas populares para aprendizado de máquina e aprendizado profundo, como TensorFlow e Keras, além de ferramentas de visualização incrivelmente poderosas, como D3.
Graças ao suporte de bibliotecas populares para aprendizado de máquina e devido à sua ampla popularidade entre os desenvolvedores web, é uma opção de entrada tranquila para todos os programadores de front-end e back-end que desejam entrar na Ciência de Dados.
C/C++
Consideradas duas das linguagens mais otimizadas, estar familiarizado com C e seu parente próximo C++ pode ser muito útil quando se trata de lidar com trabalhos de Ciência de Dados computacionalmente intensivos.
C e C++ são comparativamente mais rápidos do que outras linguagens de programação, tornando-os candidatos adequados para desenvolver aplicativos de Big Data e aprendizado de máquina. Não é coincidência que alguns dos principais componentes de bibliotecas populares de aprendizado de máquina, incluindo PyTorch e TensorFlow, sejam escritos em C++.
Devido à sua natureza de nível um pouco mais baixo, C e C++ estão entre as linguagens mais complicadas de aprender. Portanto, embora possam não ser as primeiras escolhas ao embarcar no mundo da Ciência de Dados, uma vez que você tenha uma sólida compreensão dos fundamentos da programação, dominá-los é uma jogada inteligente que pode fazer uma grande diferença no seu currículo.
Swift
Uma das desvantagens do Python e do R é que nenhum deles foi construído com mobile em mente. Nos próximos anos, podemos esperar um avanço ainda maior de dispositivos móveis, wearables e IoT (Internet das Coisas).
O Swift foi desenvolvido pela Apple para facilitar a criação de aplicativos e, com isso, crescer seu ecossistema de apps e aumentar a retenção de clientes. Logo após seu lançamento em 2014, Apple e Google começaram a trabalhar juntos para torná-lo uma ferramenta-chave na interação entre mobile e machine learning.
O Swift agora é compatível com o TensorFlow e interoperável com o Python. Uma vantagem adicional do Swift é que ele não está mais limitado ao ecossistema iOS e se tornou código aberto para funcionar no Linux.
Por esses motivos, se você é um desenvolvedor mobile e tem curiosidade sobre Ciência de Dados, o Swift é uma opção interessante para dominar.
GoLang
GoLang, ou apenas Go, é uma linguagem com crescente popularidade, especialmente para projetos de aprendizado de máquina. O Google o introduziu em 2009 com sintaxe e layouts semelhantes ao C. De acordo com muitos desenvolvedores, Go seria uma versão moderna “à la século XXI” do C.
O Go está se tornando extremamente popular devido à sua linguagem flexível e fácil de entender. No contexto da Ciência de Dados, o Go pode ser um bom aliado para tarefas de aprendizado de máquina. Apesar de suas perspectivas, a comunidade de Ciência de Dados do Go ainda é muito pequena.
MATLAB
MATLAB é uma linguagem projetada principalmente para computação numérica. Amplamente adotado na academia e na pesquisa científica desde seu lançamento em 1984, o MATLAB fornece ferramentas poderosas para realizar operações matemáticas e estatísticas avançadas, tornando-o um ótimo candidato para Ciência de Dados.
No entanto, o MATLAB tem uma grande desvantagem: é uma linguagem proprietária (comercial). Dependendo do caso (uso acadêmico, pessoal ou empresarial), você pode ter que pagar uma grande quantia para obter uma licença, tornando-a menos atraente do que outras linguagens de programação que podem ser usadas gratuitamente.
Apesar disso, se você tiver tempo e disposição, pode valer a pena aprender essa linguagem para incrementar o seu currículo.
SAS
SAS (Statistical Analytical System) é um ambiente de software projetado para inteligência de negócios (Business Intelligence) e computação numérica avançada. O SAS existe há muito tempo e é amplamente adotado em grandes empresas nos mais diversos setores, criando um grande mercado para desenvolvedores de SAS.
No entanto, o SAS está perdendo popularidade em relação a outras linguagens de programação de Ciência de Dados, como Python e R. Isso ocorre principalmente porque, como ocorre com o MATLAB, você precisa de uma licença para usar o SAS. Isso cria uma barreira à entrada de novos usuários e empresas, que se sentirão propensos a usar linguagens gratuitas e de código aberto.
Rust
Rust é uma linguagem de programação moderna que foi projetada com foco em segurança e desempenho. Lançada em 2010, ela se destaca por evitar vulnerabilidades comuns que podem ocorrer em outras linguagens, como vazamentos de memória e falhas de concorrência. Isso é especialmente valioso em projetos de Ciência de Dados que requerem alta confiabilidade e eficiência.
Principais características da linguagem Rust que a tem feito crescer na comunidade de Data Science:
1. Segurança de memória: Rust implementa um sistema de propriedade de memória que garante que as regras de acesso e gerenciamento de memória sejam seguidas em tempo de compilação. Isso elimina uma grande classe de bugs, tornando os programas mais seguros.
2. Desempenho: Rust é compilado diretamente em código de máquina, resultando em desempenho comparável ao de C e C++. Para aplicações que lidam com grandes volumes de dados ou que exigem processamento intensivo, essa característica é fundamental.
3. Concorrência: A linguagem foi projetada para facilitar a execução concorrente de código, permitindo que as aplicações aproveitem melhor os múltiplos núcleos de CPU, o que é crítico em tarefas de processamento de dados em larga escala.
4. Ecossistema emergente: Embora Rust ainda esteja em desenvolvimento em termos de bibliotecas para Ciência de Dados, já existem algumas ferramentas promissoras. Por exemplo:
- Polars: Uma biblioteca de DataFrame otimizada para manipulação de dados que se destaca em velocidade e eficiência. Inspirada no Pandas, Polars permite o processamento paralelo e movimentação eficiente de dados em grande escala.
- Arrow: Proporciona uma representação em memória da coluna que pode ser utilizada para processamento em várias linguagens, incluindo Rust. Isso é particularmente vantajoso para análise de dados complexos e operações de aprendizado de máquina.
5. Integração com corpos de dados: Rust pode ser facilmente integrado com outras linguagens, permitindo que partes de um projeto sejam escritas em Rust para desempenho crítico, enquanto outras partes podem ser desenvolvidas em Python, por exemplo. Isso possibilita uma abordagem híbrida que combina a facilidade de uso de outras linguagens com a eficiência de Rust.
Algumas aplicações de Rust em Ciência de Dados:
- Processamento de dados em tempo real: Devido à sua natureza eficiente e capacidade de manipular dados rapidamente, Rust é adequado para aplicações que exigem análise em tempo real, como sistemas de recomendação e monitoramento de dados.
- Construção de ferramentas e bibliotecas: Com um crescente interesse em ferramentas de aprendizado de máquina, Rust pode ser utilizado para desenvolver bibliotecas que ofereçam alta performance em operações matemáticas e estatísticas.
- Ambientes de alta confiabilidade: Rust é ideal para aplicações onde a segurança e a confiabilidade são críticas, como em análises financeiras e em campos onde erros podem ter consequências substanciais.
Rust está ganhando espaço na Ciência de Dados, particularmente em áreas onde o desempenho e a segurança são cruciais. Embora o ecossistema ainda esteja em desenvolvimento, as bibliotecas já disponíveis estão demonstrando que Rust pode ser uma opção viável para cientistas de dados que buscam maximizar a eficiência e a segurança de suas aplicações. À medida que mais desenvolvedores adotam Rust e contribuem para sua comunidade, é provável que a linguagem se torne uma ferramenta cada vez mais relevante no arsenal de um cientista de dados.
E aí, causou surpresa alguma dessas linguagens na lista? Não importa qual ou quais linguagens você escolha para trabalhar. O mais importante é dominá-la o suficiente para apresentar as soluções para os problemas que você terá como cientista de dados.
Mais de 70 cursos completos na área de Ciência de Dados, Big Data, Engenharia de Dados e Inteligência Artificial: OPORTUNIDADE IMPERDÍVEL, CONFIRA!
Veja também:
- Como utilizar o feedback dos clientes para melhorar seu serviço
- A importância da diversidade e inclusão nas empresas: um caminho para o sucesso
- Como desenvolver um pensamento crítico em sua carreira
- Conheça 13 ferramentas essenciais para empreendedores iniciantes
- O que é Empreendedorismo Social e como ele está mudando o mundo